Let's try a non-trivial example. Consider two problems:
- Problem $A$ is to sort $n$ integers.
- Problem $B$ is to find the convex hull of $n$ points.
We know that sorting is in $\Omega(n \log n)$. But what about convex hull?
If we could reduce sorting to convex hull, we would know that convex hull is also in $\Omega(n \log n)$.
So ... given $n$ integers to be sorted, how can we convert the integers into a set of points (i.e. the input to the convex hull problem) such that the convex hull of those points gives us the sorted order of the original integers?
And the answer is ... for each integer, $i$, to be sorted, provide a corresponding point $(i,i^2)$ to the convex hull problem.
Suppose we have the integers $\{5,1,7,2,10\}$. Then the corresponding points would be
$$\{ (5,25), (1,1), (7,49), (2,4), (10,100) \}.$$
which look like this (scaled a bit in the $y$ direction):

And their convex hull would be:
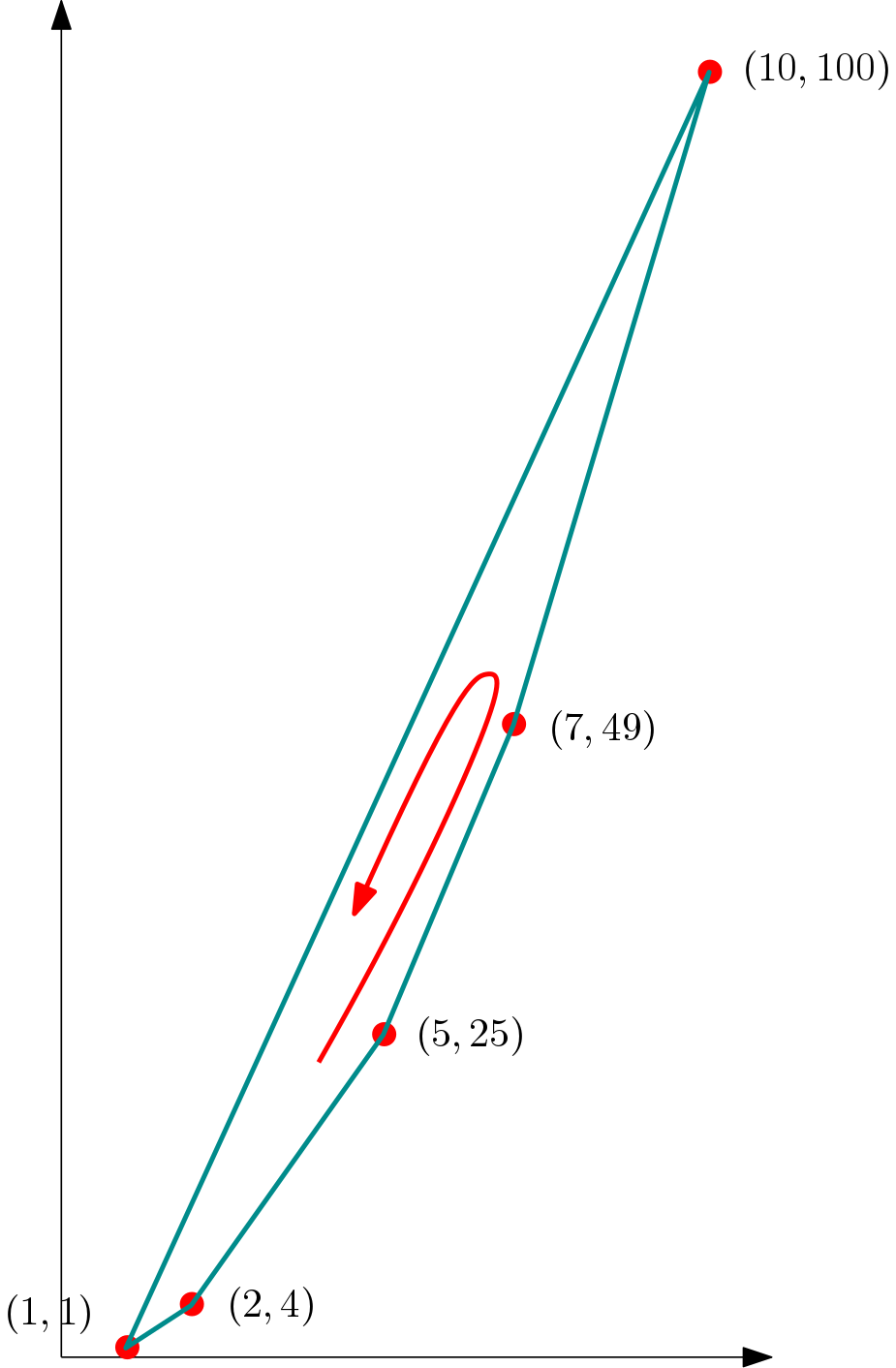
Given the convex hull, we can walk around it to gather the points in order (since the solution to the convex hull problem is an ordered set of points on the hull).
Suppose we start walking at $(5,25)$. Then the sequence of points is
$$\langle\ (5,25), (7,49), (10,100), (1,1), (2,4)\ \rangle.$$
We can extract only the $x$ components to get
$$\langle\ 5, 7, 10, 1, 4\ \rangle$$
and label those as $x_1$ to $x_n$:
$$\langle\ x_1, x_2, x_3, x_4, x_5\ \rangle$$
Then we find the index, $i$, of minimum value. In this case the minimum value is $x_4 = 1$ and its index is $i = 4$.
So the sorted sequence is
$$\langle\ x_i, x_{i+1}, \ldots x_n, x_1, x_2, \ldots, x_{i-1}\ \rangle.$$
Analysis
The conversion from $A$ (sorting) to $B$ (convex hull) took $\Theta(n)$ time, since each integer was replaced by a point.
The conversion of the solution back from $B$ to $A$ also took $\Theta(n)$ time because it required (a) walking around the hull of $n$ points and extracting the $x$ values, then (b) finding the minimum of $n$ points, then (c) copying two parts of the list to the output.
So we can reduce $A$ to $B$ in $\Theta(n)$ time.
Since we know that $A$ is in $\Omega(n \log n)$, we have proven that $B$ is also in $\Omega(n \log n)$.
Thus, there is no algorithm to compute the convex hull of $n$ points that runs in better than $\Omega(n \log n)$.
This is an amazing conclusion, as it's a claim about all possible algorithms, even those not yet invented!